Research on the Ecological Impact of Datasets
by Alexander Taylorwebsite - instagram
Rather than printing a photograph to save it for perpetuity, we upload it to the cloud. It’s better for the environment, we proudly state. Yet Alexander’s research shows us that our digital behaviours have a largely hidden environmental footprint of their own. In fact the data centres that contain our personal snapshots (and so much more) currently account for more than 2% of the global deman for electricity. Our data takes on a second life as it’s then used to train machine learning models – for the purposes of advertising, or otherwise – creating a flywheel effect as the amount of data collected and stored rises exponentially.
To help demystify this ‘invisible’ climate force, Alexander has created a game in which we train our own learning machine and try to monetise this AI, with all-out climate catastrophe being one of the many outcomes. Alexander playfully illustrates the way in which the corporate obsession with mass data harvesting can lead to not just a loss of privacy, but environmental degradation. Our planet’ well-being is not the priority of those designing the tools that determine the future of our internet.
The game subtly outlines the extent to which the values and perspectives of our machines mirror those of the humans that program them; they are embedded with a human-centric view of the world, when they could potentially offer alternative perspectives. We have inserted our most harmful traits and biases into the data used to train our machines, using these to predictable profit-driven ends – yet if the machines can be programmed to serve surveillance capitalism, could they not also be programmed to see in such a way that offers perspectives and solutions outside of our current thinking?
To help demystify this ‘invisible’ climate force, Alexander has created a game in which we train our own learning machine and try to monetise this AI, with all-out climate catastrophe being one of the many outcomes. Alexander playfully illustrates the way in which the corporate obsession with mass data harvesting can lead to not just a loss of privacy, but environmental degradation. Our planet’ well-being is not the priority of those designing the tools that determine the future of our internet.
The game subtly outlines the extent to which the values and perspectives of our machines mirror those of the humans that program them; they are embedded with a human-centric view of the world, when they could potentially offer alternative perspectives. We have inserted our most harmful traits and biases into the data used to train our machines, using these to predictable profit-driven ends – yet if the machines can be programmed to serve surveillance capitalism, could they not also be programmed to see in such a way that offers perspectives and solutions outside of our current thinking?

Creative Proposition: Face Manager 2000
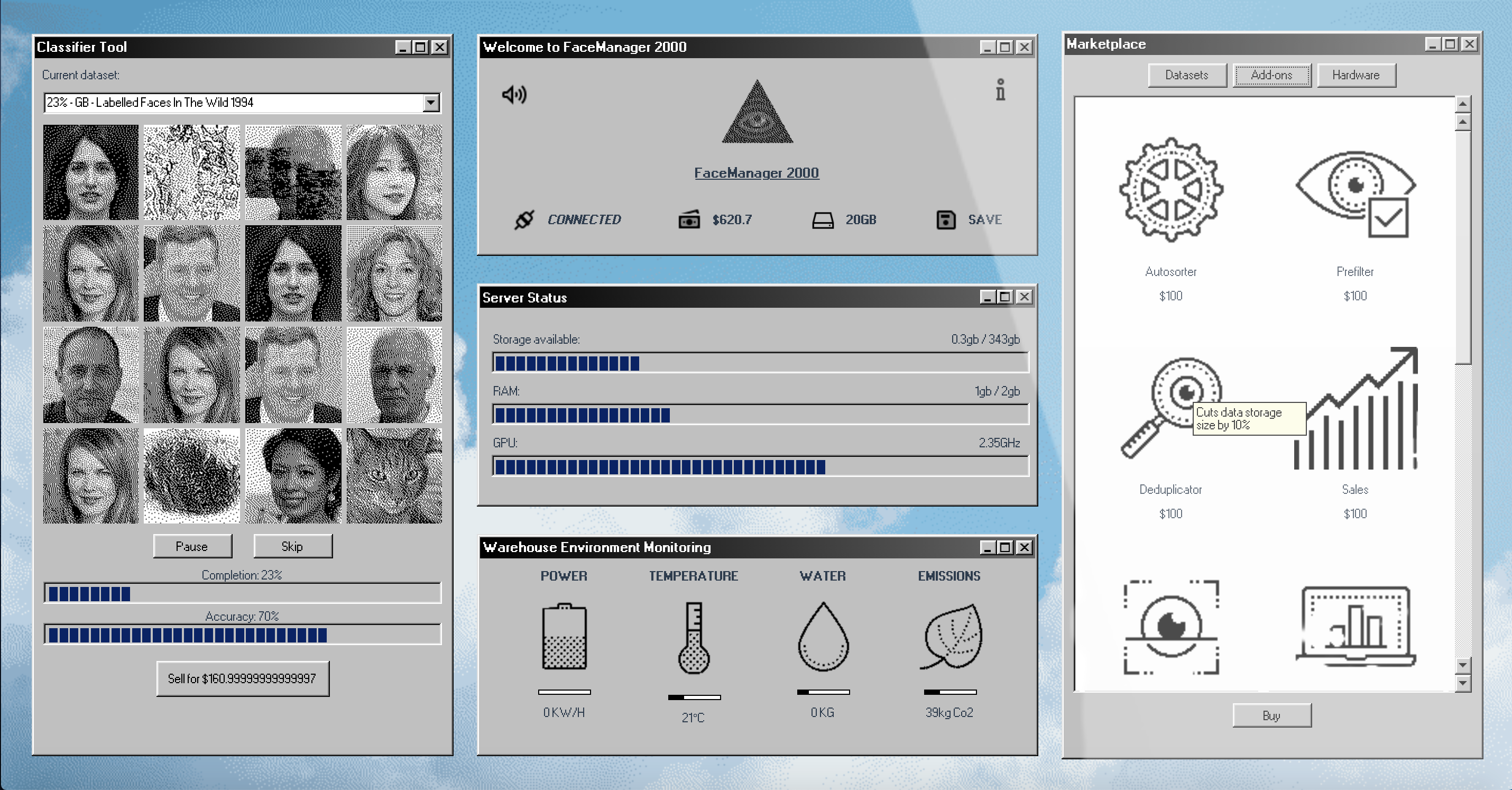
Experimental video gameFaceManager 2000 is an exploration into how the simulation game format can be used to break down an incredibly complex topic – one that spans the topics of surveillance, A.I., and the physical infrastructure that enables their deployment at extreme scales. One can feel helpless when reading about such gargantuan systems; a game can temporarily allow the suspensio of reality, putting the player in the position of power.
Inspired by the viral success of ‘incremental games’ like Cookie Clicker and Idle Oil Tycoon, it uses exponential growth as a game mechanic to highlight the winner-takes-all reality of cloud computing, where datasets and the server farms that contain them grow sharply year-on-year in both their scale and value. The digital terrains on which these technologies are constructed, and virtual clouds from which
they deployed, makes it hard to connect them to the physical realities of raw computational power, yet the impact of this consumption is palpable.
By representing a simplified version of the present-day mechanics of machine learning model creation within the visual language of late-90s software, the aim is to make the intangible feel familiar, and even kitsch. Web scraping, bias, and surveillance all play a role in building your data collection; ‘iconic’ datasets from history play cameo roles in your A.I. system as you collate and classify facial data to train your models, mapping out a brief history of facial recognition technology.
Energy and water usage is tracked and monitored within the game; the player must juggle warehouse cooling systems, hardware upgrades, regulatory forces and carbon offsets while carving out their AI empire – at a cost which becomes clearer only as the game progresses.
Inspired by the viral success of ‘incremental games’ like Cookie Clicker and Idle Oil Tycoon, it uses exponential growth as a game mechanic to highlight the winner-takes-all reality of cloud computing, where datasets and the server farms that contain them grow sharply year-on-year in both their scale and value. The digital terrains on which these technologies are constructed, and virtual clouds from which
they deployed, makes it hard to connect them to the physical realities of raw computational power, yet the impact of this consumption is palpable.
By representing a simplified version of the present-day mechanics of machine learning model creation within the visual language of late-90s software, the aim is to make the intangible feel familiar, and even kitsch. Web scraping, bias, and surveillance all play a role in building your data collection; ‘iconic’ datasets from history play cameo roles in your A.I. system as you collate and classify facial data to train your models, mapping out a brief history of facial recognition technology.
Energy and water usage is tracked and monitored within the game; the player must juggle warehouse cooling systems, hardware upgrades, regulatory forces and carbon offsets while carving out their AI empire – at a cost which becomes clearer only as the game progresses.